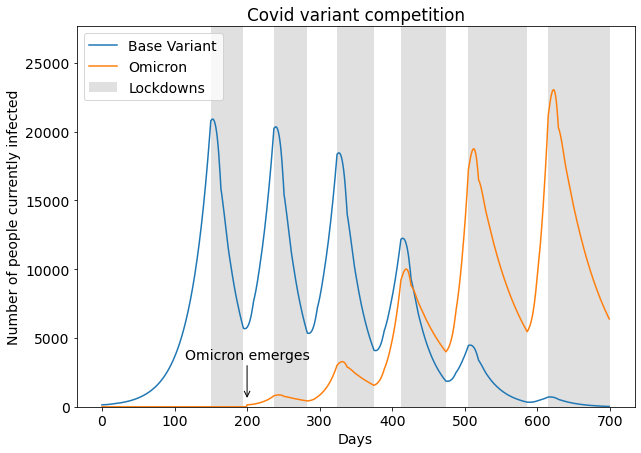
Separate development feedback and performance evaluation
Development feedback—intended to help team members learn and improve—needs an environment where the recipient can absorb information. This requires psychological safety: no blame, no pressure, no personal attacks, no consequences, no reason to get defensive.
Performance evaluation—informing employees how happy the company is with their output—is a high-stakes and high-stress situation that precludes learning.
While both are important, they're distinct types of communication:
| Development Feedback | Performance Evaluation | |
|---|---|---|
| Goal | Learning and information gain | Assessment and rating |
| Scope | Feedback on a specific action, close in time to the actual performance | Feedback on performance over a longer duration |
| Frequency | Daily-weekly: whenever reviewing a report's work output | Quarterly/yearly or on-demand when performance problems arise |
| Level | Often about details, such as: missing error handling code, a better way to do X, better wording for customer communication | Higher-level, such as: progress toward yearly goals, or work output over the last weeks |
| Stakes | Low stakes: "you are not your code" | High stakes: career progress or negative consequences |
| Formality | Informal and usually verbal | More formal and usually documented in writing |
| Consistency | Individual feedback for each team member | Fairness requires consistent success criteria for all team members |
| Preparation | Little or no preparation necessary: a casual discussion | Fair evaluation requires research and preparation |
It's easy to slip a performance remark into a feedback discussion, but it's a mistake. The employee will focus on the performance aspect and not on learning.
Off-hand, negative performance evaluations are especially damaging. They encourage a defensive, argumentative mindset which precludes learning. They also risk escalating into a larger performance discussion you're not prepared for.
Here are some examples of what to avoid:
- BAD: Your code is missing error handling. You seem distracted recently.
- BAD: Your presentation was hard to follow. This way you'll never reach your sales quota.
- BAD: Your customer email sounded rude. I'm fairly unhappy with your work at the moment.
If general performance concerns arise during a feedback session, wrap up as usual, schedule a separate performance talk, and prepare accordingly.
An example of a better approach:
- GOOD:
- Feedback session: Here are some points you could improve in your project proposal: «detailed explanation».
- Performance discussion a day later in private: I had the impression that your recent work is less polished then it used to be. Is everything alright?
Decide up-front which discussion you will have: feedback to help your reports grow or performance evaluation. Avoid mixing the two and pick the right approach and setting for each.